像DALL-E这样的文本到图像合成模型可以将输入的字幕转换成连贯的可视化。然而,许多应用程序需要处理长篇叙述和隐喻表达,以现有视觉为条件,并生成不止一张图像。
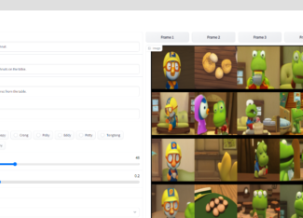
在 Pororo 数据集上训练的 mega-StoryDALL-E 的公开可用浏览器内演示的快照。右侧面板显示模型为用户在左侧面板中输入的字幕生成的图像。
因此,最近在 arXiv.org 上发表的一篇论文探讨了为复杂的下游任务调整预训练的文本到图像合成模型的方法,重点是故事可视化。
研究人员提出了一项新任务,故事的延续。在此任务中,提供了一个初始场景,然后模型可以在生成后续图像时从中复制和调整元素。此外,预训练模型(如 DALL-E)在顺序文本到图像生成任务上进行了微调,具有从先前输入复制的额外灵活性。
改编版名为 StoryDALL-E,在多个指标上优于标准的基于 GAN 的模型。